

Pareto Analysis
A technique that separates important causes from trivial causes


The Pareto Analysis is a technique that separates important causes from trivial causes. It is named after Vilfredo Pareto an Italian 19th century sociologist and economist who in 1897 argued that the distribution of income and wealth is uneven and follows a regular pattern that can be represented by a mathematical formula. In 1907 a similar theory was expressed diagrammatically by the American economist M. C. Lorenz. Both demonstrated that by far the largest share of a nation's wealth is owned by a very small proportion of the people. But it was Juran (one of the original quality gurus who went to Japan in the 1950s) who realised that Lorenz's diagram and Pareto's formula - also known as the 80-20 rule - could be observed in other fields. For example:
80 per cent of customer complaints could come from 20 per cent of the customers;
80 per cent of accidents could be generated by one age group;
80 per cent of the cost could be accounted for by 20 per cent of the parts.
It doesn't have to be an exact 80-20 split for every set of circumstances you investigate. It could be 90-10, 70-30 or 60-40. The important things to remember is that where there is an uneven distribution of causes and effects we can separate the 'significant few' from the 'trivial many' and we can put our efforts into where they will have the biggest effect. The basic concept behind a Pareto analysis involves ranking data. Similar to a bar chart, a Pareto diagram shows a distribution, but it also necessitates ordering information from the largest to the smallest: the most significant to the most trivial.
Often the raw data is recorded on the left vertical axis with the percentage scale on the right vertical axis. Make sure that the two axes are drawn to the same scale so that the 100 per cent corresponds to the total on the left-hand scale.
Pareto diagrams can be used with or without a cumulative line. When cumulative lines are used, they represent the sum of the vertical bars, as if they were stacked on each other going from left to right. In this way you can answer questions such as: 'Which causes, when taken together, make up 80 per cent of the problem?' or 'What percentage of the total is accounted for by the first three categories?'
Constructing a Pareto diagram
The Pareto diagram is constructed in five steps:
Decide how the data should be classified
Use a check chart to collect the data
Summarise data from the check chart
Construct a bar graph with the tallest bar on the left and the shortest on the right
Plot cumulative amounts using a single line
Let me show you an example of how this works. Can you imagine a computer network which keeps on breaking down? In order to investigate this problem you would have start by collecting data. The tool that's usually used for this is called a check chart. It's just a form that has been ruled up so that you can collect the data you want.
The breakdowns will be given an incident number in the first column, times at which the network breaks down will be shown in the second column, the times at which the network is up again will be in the third column and the downtime for each outage will be shown in the fourth column.
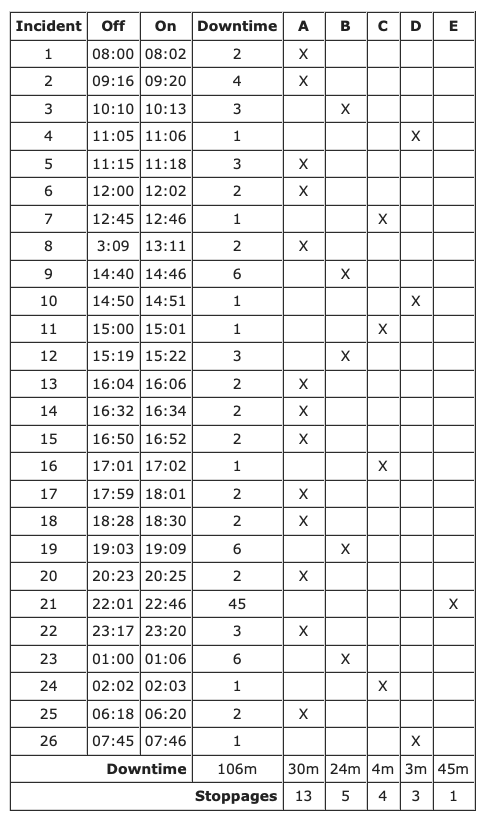
The columns headed by A, B, C, D and E represent the reasons for the breakdowns. So, the first time that the network broke down was for reason A, the second time was also for reason A, but the third stoppage was for reason B. The network broke down a total of 26 times and the total down time was 106 minutes.
As a mass of figures do not mean much in themselves, the next step is to display the data.
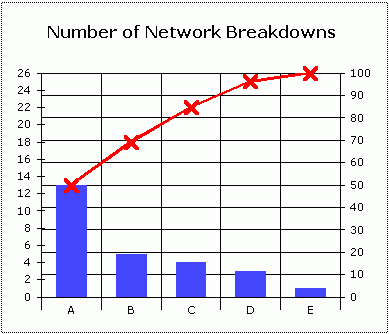
When you do a Pareto analysis, the most significant effect is shown on the left-hand side and the least significant effect is shown on the right-hand side.
A percentage scale is added to the chart, so the 26 stops correspond to 100 per cent and reason A accounts for 50 per cent of the stops.
If you add reason B to reason A, you will have accounted for nearly 70 per cent of the problem. You can see that if you were to put as much effort into eliminating the two least significant causes as you do into the two most significant causes, you would only solve 15 per cent of the problem as opposed to 70 per cent.
Deciding how the data should be classified is very important as it can make a great difference to the analysis. In the example above we decided that the data should be classified according to the number of breakdowns attributable to each of the causes. This classification is fine if the problem you are investigating is one of the computer network breaking down too often. But what if the problem were one of the network being down for too long. In this case you would be interested in the duration of the breakdowns and which causes caused the longest outages.
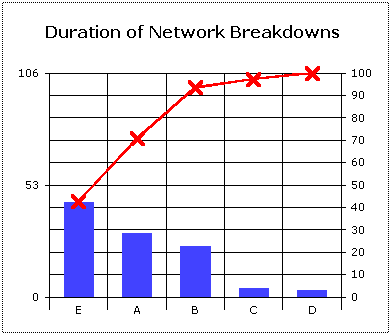
Here you can see that reason A has dropped from first place and reason E has come up from behind to take first place. This underlines the importance of working on the right problem because, depending on the problem, you would attack different sets of causes.
Paid subscribers can download PDF and ePub versions of this article
Paid subscribers have early access to new articles
I wanted to say as an engineer I use this principle every day and teach it to young engineers - but after reading your clear explanation I realized: I never really understood it correctly. It is not just a case of focusing your efforts on 80% of the problems / risks and forgetting about the 20%. It is identifying the 20% that causes the 80% and address those. And here I am touting 'risk-based' approaches every day! Will have to go back and check all those aircraft and ships I built! Thank you for a great piece! :-)